In den letzten 50 Jahren haben sich die Fortschritte in der Informationstechnologie und ihren Anwendungen darauf konzentriert, bestehendes Wissen und Verfahren zu kodifizieren und in Maschinen zu integrieren. Maschinelles Lernen (ML) überwindet diese Grenzen. Nunmehr lernen Maschinen anhand von Beispielen und mithilfe von strukturiertem Feedback ihre eigenen Probleme zu lösen. Hinzu kommen die mittlerweile hohen Rechenkapazitäten sowie der Zugriff auf große Datenmengen. Beides sind wesentliche Voraussetzungen für lernende Systeme und die zugrunde liegenden Algorithmen.
ML-Algorithmen unterstützen den Menschen, Muster in vorhandenen Datenbeständen zu erkennen, Prognosen vorzunehmen oder Daten zu klassifizieren. Mit mathematischen Modellen können neue Erkenntnisse auf Grundlage dieser Muster gewonnen werden. Dafür steht ein breites Spektrum an Verfahren des Maschinellen Lernens zur Verfügung, wie die Lineare Regression, Entscheidungsbaum-Algorithmen, Bayesche Statistik, Clusteranalyse, Neuronale Netzwerke oder Deep Learning. Diese Verfahren kommen immer stärker auch im Banking zum Einsatz, wie beispielsweise in der Spam-Erkennung, bei der Personalisierung von Inhalten, dem Klassifizieren von Dokumenten, bei der Anwendung von Sprachassistenten oder in der Betrugserkennung.
Return nur schwer messbar
Insbesondere IT-Entscheider glauben an das Potenzial des Maschinellen Lernens. Häufig gibt es allerdings Schwierigkeiten, wenn es um den Nachweis geht, ob sich der Einsatz eines ML-Verfahrens tatsächlich in der Praxis rechnet. Nach Umfragen berichtet nur einer kleiner Teil der ML-Anwender von einem konkreten Return on Investment (RoI) der eingesetzten ML-Systeme. Hinzu kommt die besondere Schwierigkeit, den RoI von Datenprojekten und Datentechnologien zu messen.
Im Folgenden wird ein methodischer Strukturierungsrahmen vorgestellt, um ein ML-Vorhaben aus verschiedenen Perspektiven zu bewerten. Zum besseren Verständnis dieses Rahmens wird ein ML-Projekt aus der Praxis ausgewählt. Es handelt sich um die Implementierung von ML bei der Geldwäschebekämpfung (AML) in einer Bank.
Kein einheitlicher Ansatz
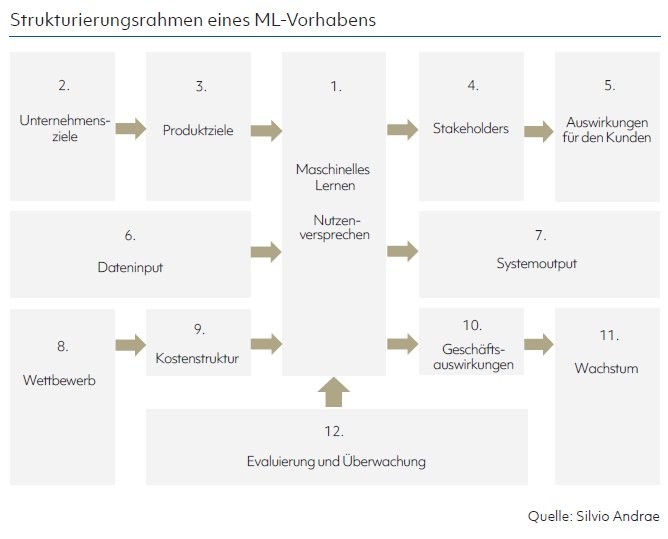
Für die Einführung eines ML-Projekts in einem Unternehmen ist ein konzeptioneller Strukturierungsrahmen erforderlich. Er dient dazu, das ML-Vorhaben ganzheitlich zu beschreiben, zu analysieren und zu bewerten. Dies geschieht in einer übersichtlichen Art und Weise. In der Praxis finden sich verschiedene solcher Strukturierungsrahmen. Einen einheitlichen Ansatz gibt es nicht. Als Grundlage für den vorliegenden Praxisfall dient der Canvas-Strukturierungsrahmen. Er wurde von Osterwalder und Pigneur entwickelt und findet vor allem bei der Analyse und Entwicklung von Geschäftsmodellen Anwendung. 1) Der Canvas-Rahmen wurde anpasst und ist in der vorgestellten Form gut geeignet, um ML-Vorhaben angemessen zu bewerten.
Entscheidungsprozess frühzeitig strukturieren
Der Nutzen besteht darin, den Entscheidungsprozess bei einer ML-Investition frühzeitig zu strukturieren. Dies gilt sowohl für das Management, das wissen möchte, ob ein Vorhaben einen Mehrwert bietet. Dies gilt aber auch für die Techniker, wenn es beispielsweise um die gemeinsame Definitionen geht. Daher ist das Instrument auch geeignet für die Kommunikation.
Der Strukturierungsrahmen besteht aus insgesamt 12 Elementen (siehe Abbildung). Sie werden im Folgenden kurz vorgestellt und durch das ML-Projekt zur Geldwäscheprävention veranschaulicht.
1. Nutzenversprechen: Das Nutzenversprechen beschreibt den Mehrwert, den die Stakeholder oder der Kunden aus dem ML-Vorhaben des Unternehmens im Vergleich zu den Wettbewerbern ziehen kann. Im Einzelnen geht es darum, welche Kundenwünsche befriedigt und Probleme der Kunde durch das ML-Vorhaben gelöst werden. Es steht nicht nur die Identifizierung des Problems im Vordergrund, sondern auch deren Einflussfaktoren und Auslöser. Das Nutzenversprechen bezieht sich in der Regel auf ein Produkt beziehungsweise eine Dienstleistung und den Umfang der versprochenen Leistung. Je präziser das Nutzenversprechen formuliert ist, desto größer werden die Stakeholder oder die Kunden dessen Wert empfinden. Bei der Neudefinition des Nutzenversprechens kann beispielsweise auf bisherige Hindernisse abgestellt werden. Deren Überwindung erzeugt einen Mehrwert für den Kunden.
Geldwäsche ist ein niederfrequentes Ereignis. Banken müssen sicherstellen, dass sie keine Geschäfte mit Kriminellen machen und dass ihre Konten nicht für Geldwäsche oder Terrorfinanzierung missbraucht werden (EU-Geldwäscherichtlinie 2018). Ein wesentlicher Teil eines AML-Compliance-Programms besteht aus der Transaktionsüberwachung. Sie zielt darauf ab, verdächtige Aktivitäten und atypische Transaktionen zu erkennen. Der Umfang der Transaktionen ist breit gefächert und umfasst unter anderem Einlagen, Auszahlungen, Geldtransfers, Handelskredite und sonstige Zahlungen.
Typischerweise erfolgt die Überwachung durch ein regelbasiertes System. Die Regeln werden ex ante definiert und umgesetzt. Regelmäßig beziehungsweise anlassbezogen werden die Schwellenwerte angepasst, um eine höchstmögliche Trefferrate von verdächtigen Kunden zu realisieren. Die Anwendung unterscheidet zwischen "positiv" (verdächtiger Kunde) und "negativ" (unverdächtiger Kunde). Anhand von bestimmten Kriterien wird eine Warnung generiert und der (positive) Fall zur manuellen Überprüfung an das interne Ermittlungsteam der Bank weitergeleitet. Der Überprüfungsprozess besteht aus einer Tiefenanalyse durch die Ermittler.
Das Standard-Transaktionsüberwachungssystem (TMS) hat große Nachteile. Die falsch-positiven Treffer, die durch dieses regelbasierte System erzeugt werden, können sehr hohe Werte erreichen. Zudem ist das System starr und berücksichtigt nur bedingt komplexe Wechselwirkungen zwischen den verschiedenen Verhaltensweisen, die zum Waschen von Geld verwendet werden. Darüber hinaus ist die Aufrechterhaltung dieses Programms teuer, was zum Teil auf die Kosten für den Einsatz eines großen Teams von Ermittlern zurückzuführen ist. All diese Faktoren motivieren, den aktuellen Transaktionsüberwachungsprozess weiterzuentwickeln, um die Erkennung effizienter zu gestalten.
ML-Algorithmen können bei der Geldwäscheprüfung helfen, auffällige Verhaltensmuster oder Missbrauch frühzeitig zu erkennen. Eine systematische Netzwerkanalyse des gesamten Transaktionsnetzwerkes fördert Anomalien, Ausreißer und Besonderheiten zutage, die klar auf kriminelle Handlungen wie Betrug und Geldwäsche hindeuten. Alle herkömmlichen Methoden kommen hier an ihre Grenzen, denn sie haben keine Kenntnis über die vernetzte Organisation von Betrug. Für den Einsatz von KI und ML gibt es noch keine Standards. Sie müssen erst noch entwickelt werden.
2. Unternehmensziele: Das Nutzenversprechen steht in enger Beziehung mit den Unternehmens- und Produktzielen. Je konkreter und kohärenter die Unternehmensziele zu den übrigen Modellelementen stehen, umso besser ist das Verständnis. Ein ML-Projekt kann aufgrund seiner Funktionalität verschiedenen Zielen entsprechen. Die Unternehmensziele werden auch beeinflusst, wenn Maschinelles Lernen ein Problem angeht, das für das Unternehmen von zentraler Bedeutung ist. Ein ML-Projekt ist aber nicht automatisch unrentabel, wenn es auf einer bestimmten Ebene nicht mit den Unternehmenszielen verbunden ist.
ML-Lösung erhöht die Trefferquote
Bei Verstößen gegen die Geldwäsche drohen den Banken hohe Strafen. Bei den aktuellen Systemen, die auf den von Experten entwickelten Erkennungsregeln basieren, ist die Quote der Fehlalarme noch sehr hoch. In der Praxis gelten die bisherigen Modelle als sehr gut, wenn sich nur 95 Prozent der Verdachtsmeldungen als Fehlalarm erweisen. Das bedeutet, dass in 5 Prozent der Fälle verdächtige Aktivitäten fälschlicherweise erkannt und 5 Prozent aller Aktivitäten nicht den festgelegten Kriterien entsprechend gekennzeichnet sind. Alle als verdächtig eingestuften Transaktionen müssen Mitarbeiter manuell überprüfen. Das ist meist nur eine Sache von jeweils wenigen Minuten, dennoch mit hohem Aufwand verbunden. Eine ML-Lösung leistet dann einen Wertbeitrag, wenn die Trefferquote erhöht wird, indem bisher unerkannte Muster identifiziert werden. Ebenso können auch kleinvolumige Transaktionen erkannt werden, die in den bisherigen Expertenlösungen unter Umständen nicht auffallen.
3. Produktziele: Bei den Produktzielen treffen die unterschiedenen Interessen des ML-Projekts aufeinander. Hier werden die ML-Metriken und die Make-or-Break-Definitionen festgelegt. Es ist darauf zu achten, dass die Produktziele nicht technisch definiert werden. Vielmehr müssen alle Beteiligten verstehen, worum es bei dem ML-Vorhaben geht. Andernfalls besteht die Gefahr, dass bei jedem Treffen kostbare Zeit verwendet werden muss, um das gemeinsame Verständnis erneut zu etablieren. Die Produktziele beschreiben den Wertbeitrag des ML für das Unternehmen und den Beitrag des ML für das betreffende Produkt. Eine zusammenhängende Geschichte bildete den roten Faden zwischen den Unternehmens- und Produktzielen und dem Nutzenversprechen durch das ML-Projekt.
Mit der ML-Lösung zur Geldwäscheprävention werden zusätzliche Compliance-Verstöße identifiziert und die Trefferquote erhöht. Durch das Hinzufügen von zusätzlichen Datenelementen und die Verknüpfung von Systemen wird eine höhere Qualität in der Überwachung erreicht. Zusätzlich soll sich die Prozessdauer verbessern.
4. Stakeholder: Die Stakeholder beschreiben die einzelnen Interessen- und Kundengruppen, die durch das Produkt oder die Dienstleistung angesprochen werden. Es werden konkrete Schritte, das Verhalten oder Stakeholder-Schlüsselindikatoren dargestellt, die vom Produkt beeinflusst werden. Im Kern geht es an dieser Stelle darum, die Auswirkungen der ML-Lösung zu verstehen, das heißt welche Anwender durch das Produkt gewinnen oder verlieren und wo es zu Konflikten kommen kann.
Die Validierung von Entscheidungen auf Basis von ML schafft Vertrauen nicht nur in Prüfungen und Audits, sondern auch zwischen den Geschäftsbereichen und Funktionen innerhalb der Bank. So werden die gut dokumentierten Prozesse eines einzelnen Geschäftsbereichs, die auf soliden Modellen, quantifizierbaren Vorteilen und laufenden Validierungsverfahren basieren, von anderen Geschäftsbereichen oder anderen wichtigen Interessengruppen wie AML-Untersuchungsteams und AML-Compliance übernommen werden. Darüber hinaus können die Ergebnisse von Validierungen als Schlüsselfaktoren bei der Identifizierung und Priorisierung von Projekten herangezogen werden.
5. Auswirkungen für den Kunden: Ein zentraler Punkt des Strukturierungsrahmens betrifft die Auswirkungen der ML-Lösung auf den Endkunden. Wie sich eine Fehlfunktion auf den Anwender auswirkt, ist ein weiterer wichtiger Punkt. Kommen innerhalb eines AML- Programms ML-Modelle zum Einsatz, so schließt das folgende Aspekte ein:
- Due Diligence des Kunden,
- Kundenrisikoeinstufung,
- Transaktionsüberwachung,
- Warn- und Risikobewertung,
- Sanktionen und Watchlist- Überprüfung sowie
- Risikobewertung der Geldwäsche.
6. Dateninput: Bei diesem Element geht es um die Daten, die mit der ML-Lösung genutzt und verarbeitet werden sollen. Die Erfolgsrate eines ML-Projekts hängt vor allem von der Qualität und der Verfügbarkeit relevanter Daten ab. Insofern kommt der genauen Beschreibung des Dateninputs eine zentrale Bedeutung zu. Dabei ist darauf zu achten, dass die Darstellung nicht ausschließlich technisch erfolgt. Zu diesem Zeitpunkt wird häufig auch festgestellt, dass die erforderlichen Daten häufig nicht vorhanden sind oder nicht generiert werden können. Dann sollte eine Bewertung der Daten vorgenommen werden, wem beispielsweise die Daten gehören und welche Governance-Richtlinien gelten.
Das ML-Projekt im Bereich der Geldwäsche verwendet als Ausgangspunkt zunächst die verfügbaren Informationen wie Kundenstamm-, Konto- und Transaktionsdaten, um auffällige Muster und Korrelation automatisch zu identifizieren. Dies schließt Informationen zum Kundenprofil, zur Demografie und zur Transaktionshistorie ein. Zusätzliche Daten von Drittanbietern und Web-Crawling können diese Informationen ergänzen und das Bild vervollständigen.
Bei dem dargestellten Ansatz handelt es sich um eine überwachte Lernmethode (supervised learning). Der Algorithmus verwendet Trainingsdaten und Feedback von Menschen, um die Beziehung von gegebenen Eingaben zu einem gegebenen Output zu lernen (zum Beispiel potenzielle Geldwäscher) identifizieren. Es ist bekannt, wie die Eingabedaten und die Art des Verhaltens klassifiziert werden, um eine Vorhersage zu treffen. Daher kommen Algorithmen zum Einsatz, um im Fall von neuen Daten erneut zu rechnen.
7. Systemoutput: An dieser Stelle wird das Format definiert, in dem das Ergebnis erzeugt werden soll. Dazu kommt eine Beschreibung, wie die Ergebnisse andere Systeme beeinflussen. Dies erleichtert die Analyse und Nachbearbeitung. Mit der Darstellung des Systemoutputs wird das Problemende erfasst, das durch die ML-Lösung behoben werden soll. Damit werden wiederum der Bezug zum Nutzenversprechen und das Wirkungspotenzial bei anderen Geschäftsproblemen hergestellt.
Maschinelle Lernsysteme weisen oft eine geringe "Interpretierbarkeit" auf. Das bedeutet, dass Menschen Schwierigkeiten haben herauszufinden, wie die Systeme ihre Entscheidungen getroffen haben. Eine zentrale Herausforderung besteht daher, dass nachvollzogen werden muss, wie die selbstlernenden Systeme zu ihrem Output kommen. Dies fordert nicht nur die Finanzaufsicht Ba-Fin in einer jüngst veröffentlichen Studie zum Einsatz von Künstlicher Intelligenz (vgl. BaFin 2018, S. 14).
Die durch den selbstlernenden Algorithmus klassifizierten Fälle werden als Prozentwert zwischen null und 100 ausgegeben. Der Wert von annähernd 100 steht für die Sicherheit, dass der Kunde kein potenzieller Geldwäscher ist. Folgende Konstellationen sind denkbar:
- Der Kunde wird korrekt klassifiziert: Er ist entweder potenzieller Geldwäscher oder er ist keiner.
- Der Kunde wird falsch eingestuft: Er wird irrtümlich als Geldwäscher identifiziert, obwohl er tatsächlich keiner ist (Beta-Fehler).
- Der Algorithmus erkennt den Geldwäscher nicht (Alpha-Fehler).
Der Modellierungsdatensatz enthält historische Alarme und deren Ergebnisse. Er muss sorgfältig aus weitgehend den gleichen Daten zusammengestellt werden, die den Gutachtern zur Verfügung gestellt werden. Ein Analytiker, der wenig oder gar keine ML-Erfahrung hat, kann dann den Modellierungsdatensatz in die automatisierte maschinelle Lernplattform einlesen, die die wichtigsten Schritte des Modellentwicklungsprozesses für ihn automatisch durchführt.
Der Analytiker wählt dann das Modell aus, das seiner Meinung nach am robustesten ist und die Performance bei den Validierungsdaten erbringt. Die Klassifikation auf Basis des ML-Algorithmus erfolgt über Schwellenwerte. Der Schwellenwert zeigt an, unterhalb derer Betrugsfälle vorhanden waren (das heißt die Schwelle, die Null False Negatives oder FN ergibt). Die True Negatives (TN) sind Fälle, in denen die Ermittler korrekt gewesen wären und keine weiteren Überprüfung notwendig sind. Alle True Positives (TP), also die tatsächlichen Betrugsfälle, wurden oberhalb des Schwellenwerts erfasst. Die daraus resultierende neue False Positive (FP) Trefferrate wird im Vergleich zur Überprüfung aller Fälle reduziert.
Systemoutput nachvollziehen
Durch das Trainieren der Algorithmen mit historischen Daten wird die optimale Klassifizierungsgrenze bestimmt. Ziel ist die Bestimmung einer optimalen Grenze, wo es die höchste Übereinstimmung zwischen der Mensch und Maschine gibt und gleichzeitig kein Alpha-Fehler vorliegt. Es ist nicht einfach, den ML-Einsatz in Bankprozessen zu regeln, wenn nicht sicher ist, wie das System seine Vorhersagen berechnet. Der Systemoutput muss nachvollzogen werden können. Daher besteht ein erheblicher Dokumentationsbedarf in Bezug den Algorithmus.
8. Wettbewerb: Dieses Element des Strukturierungsrahmens befasst sich mit der Analyse des Wettbewerbsumfelds. Dabei geht es nicht nur darum, andere Optionen für die ML-Lösung zu identifizieren, sondern auch zu wissen, welche Lösung Wettbewerber bereits implementiert haben. Möglicherweise gibt es Wettbewerber, die nicht unmittelbar als solche auftreten. Unter Umständen werden auch Partnerunternehmen erkannt, die wesentliche Ressourcen zur Verfügung stellen und zur Risikoteilung beitragen. Die Bedeutung von kollektiven Lösungen für gemeinsame Probleme nimmt auch in der Finanzbranche zu, um den Bedarf an Datensätzen zu decken (siehe WEF 2018, S. 36).
Wird die ML-Lösung autark vom Unternehmen erstellt, ist unter Umständen mit einer hohen Ressourcenbindung und mit anderen Nachteilen zu rechnen. Diese Gefahren können vermindert werden, indem sich das Unternehmen auf die Aktivitäten konzentriert, die es in Relation zum Wettbewerber besonders gut beherrscht. Im Gegensatz dazu kann das Eingehen einer Kooperation für die ML-Lösung mit einem zusätzlichen Know-how-Transfer verbunden sein.
Der Wettbewerb wird die Banken dazu veranlassen, ihre Systeme durch ML zu verbessern, und zwar unabhängig davon, ob Compliance-Teams über das entsprechende Fachwissen verfügen oder nicht. Diejenigen, die sowohl für die Erfüllung regulatorischer Verpflichtungen als auch für die Weiterentwicklung der traditionellen, regelbasierten Ansatzes des Unternehmens verantwortlich sind, müssen eine Entscheidung über den besten Weg treffen, um das maschinelle Lernen in ihre Praxis zu integrieren.
9. Kostenstruktur: Die Kostenstruktur spiegelt die wesentlichen aktuellen und zukünftigen Aufwendungen wider, die durch die Realisierung der ML-Lösung anfallen. Darunter fallen im Allgemeinen Personal- und Verwaltungsaufwendungen oder IT-Kosten. Eine Investition in eine ML-Lösung oder in ML-intensive Produkte erfordert gewissenhafte Entscheidungen in Bezug auf die Finanzierung eines solchen Projekts. Der Beitrag zum Nutzenversprechen ist nicht immer gleich am Anfang des Produkts "sichtbar". Die Kostenschätzungen für die Entwicklung einer Lösung hängen nicht von der Programmierleistung ab. Einige Lösungen können einfach entwickelt, aber kostspielig zu testen sein. Die sachgerechte Darstellung soll dazu dienen, die richtigen Erwartungen zu erfüllen. Die Kostenermittlung erfolgt vor allem auf Basis des Dateninput und des Wettbewerbsumfelds.
Eine ML-Lösung kann die bisher hohen Aufwendungen im Bereich der Geldwäsche stark reduzieren (vgl. Kaminski/Schonert, 2018). Diese Aufwendungen sind vor allem auf die manuelle Handhabung der Überprüfung zurückzuführen.
10. Geschäftsauswirkungen: Die Auswirkungen der ML-Lösung auf das Geschäft können direkter oder indirekter Natur sein. Ist der Einfluss der ML-Lösung signifikant für das Geschäft, kann die Verbindung direkt zu den Unternehmens- und Produktziele sowie das Nutzenversprechen hergestellt werden. Ist der Einfluss hingegen eher diffus, kann der Bezug zu den Stakeholder oder den Verbraucher vorgenommen werden.
11. Wachstum: Jenseits von spezifischen Stakeholder-Betrachtungen kann ein ML-Produkt das Potenzial haben, sich zu erweitern. Die Verbindung zwischen dem aktuellen Nutzenversprechen, den erwarteten Auswirkungen auf das Unternehmen und den Wachstumsmöglichkeiten führt dazu, dass alle beteiligten Akteure die vorgegebene Richtung teilen können.
12. Evaluierung und Überwachung: Im letzten Canvas-Element wird transparent gemacht, welche Faktoren maßgeblich die Funktionsfähigkeit der ML-Lösung sicherstellen. Häufig werden beispielsweise festgefahrene ML-Modellierungen, fehlerhafte Datenquellen oder instabile Beziehungen zwischen den Tests und der Produktion als kritische Faktoren identifiziert. Das kann es schwierig, wenn nicht unmöglich machen, mit absoluter Sicherheit zu beweisen, dass das System in allen Fällen funktionieren wird. Dies gilt insbesondere in Situationen, die in den Trainingsdaten nicht dargestellt wurden.
Die ML-Modelle existieren nicht in einem Silo. Sie sind eingebettet in ein breiteres AML-Programm der Bank. Die Modelle sind datenabhängig von "Data Warehouses" und Geschäftsberichte und -prozessen, die für eine Reihe von Anwendungen verwendet werden.
ML-Modelle existieren nicht in einem Silo
Der dargestellte Canvas-Strukturierungsansatz fokussiert auf das Design aus vernetzten Aktivitäten, die anhand der einzelnen Elemente erklärt und untersucht werden können. Er stellt das Nutzenversprechen in den Mittelpunkt.
Zudem werden alle weiteren wesentlichen Punkte der Werteermittlung, einschließlich der finanziellen Aspekte einbezogen. Ferner können auf dieser Basis Handlungsempfehlungen abgeleitet werden. Dies erleichtert die unmittelbare Anwendung des Strukturierungsrahmens in der Praxis. Gleichwohl lassen sich die einzelnen Elemente im Umfang und Detailierungsgrad unternehmensspezifisch anpassen. Der Ansatz eigne sich somit in besonderer Weise in der Finanzbranche, wenn es um die Anwendung und Entwicklung von ML-Lösungen geht.
Der Vorteil maschinenbasierter Systeme besteht darin, dass sie im Laufe der Zeit verbessert werden können und bei identischen Daten konsistente Antworten liefern. Entscheidungen müssen mit gut dokumentierten Begründungen und Beweisen untermauert und verfolgt werden, um zu beurteilen, ob die Annahmen zunächst und im Laufe der Zeit wahr sind.
Bisherige Systeme berücksichtigen oft keine Wechselwirkungen
Die bisher existierenden regelbasierten Überwachungssysteme zur Geldwäscheprävention berücksichtigen häufig keine komplexe Wechselwirkungen zwischen den verschiedenen Verhaltensweisen, die zur Geldwäsche verwendet werden. ML-Lösungen können diese Compliance-Prozesse effektiver und effizienter machen, indem die Trefferquote erhöht und gleichzeitig die manuelle Überprüfung reduziert wird.
Das dargestellte Vorgehen ist erst ein erster Schritt, wie automatisierte ML-Techniken genutzt werden kann, um ein AML-Compliance-Programm zu verbessern. Mithilfe einer 360-Grad-Ansicht sind Banken in der Lage, schnell, einfach und zuverlässig eine umfassende Datenanalyse durchzuführen, zum Beispiel um wirklich verdächtige Aktivitäten zu identifizieren, die Kundenrentabilität zu bewerten oder negative Trends frühzeitig zu erkennen.
Literatur
Andrae, S. (2017): Geschäftsmodelle im Banking: Analyse und Weiterentwicklung im Banking, Stuttgart: Schäffer-Poeschel.
Bundesanstalt für Finanzdienstleistungsaufsicht (BaFin) (2018): Big Data trifft auf Künstliche Intelligenz: Herausforderungen und Implikationen für Aufsicht und Regulierung von Finanzdienstleistungen, Konsultationsentwurf Juni 2018.
EU-Kommission (2018): Richtlinie (EU) 2018/843 des Europäischen Parlaments und des Rates vom 30. Mai 2018 zur Änderung der Richtlinie (EU) 2015/849 zur Verhinderung der Nutzung des Finanzsystems zum Zwecke der Geldwäsche und der Terrorismusfinanzierung und zur Änderung der Richtlinien 2009/138/EG und 2013/36/EU, Abl. L 156/43 vom 19.06.2018.
Kaminski, P./Schonert, J. (2018): Monitoring Money-Laundering Risk With Machine Learning, in: McKinsey Quarterly Nr. 2, S. 11-12.
Osterwalder, A./Pigneur, Y (2010): Business Model Generation, Hoboken: John Wiley & Sons.
World Economic Forum (WEF) (2018): The New Physics of Financial Services: Understanding How Artificial Intelligence Is Transforming the Financial Ecosystem, August 2018.
Fußnote
1) Für die Analyse und Weiterentwicklung von Geschäftsmodellen im Banking vergleiche Andrae (2017).